
هوش مصنوعی (AI) و یادگیری ماشین (Machine Learning) به عنوان فناوریهای پیشرفته، در حال تغییر چشمانداز بسیاری از صنایع و جنبههای زندگی روزمره ما هستند. این فناوریها به ما این امکان را میدهند که از دادهها برای پیشبینی، تصمیمگیری و بهبود فرآیندها استفاده کنیم. با این حال، یکی از چالشهای جدی که در این زمینه وجود دارد، سوگیری دادهای (Data Bias) است. سوگیری دادهای میتواند به نتایج نادرست و تبعیضآمیز منجر شود و اعتماد عمومی به سیستمهای هوش مصنوعی را کاهش دهد. در این مقاله، به بررسی مفهوم سوگیری دادهای، انواع آن، تأثیرات آن بر سیستمهای هوش مصنوعی و راهکارهای مقابله با آن خواهیم پرداخت.
1. مفهوم سوگیری دادهای
1.1 تعریف سوگیری دادهای
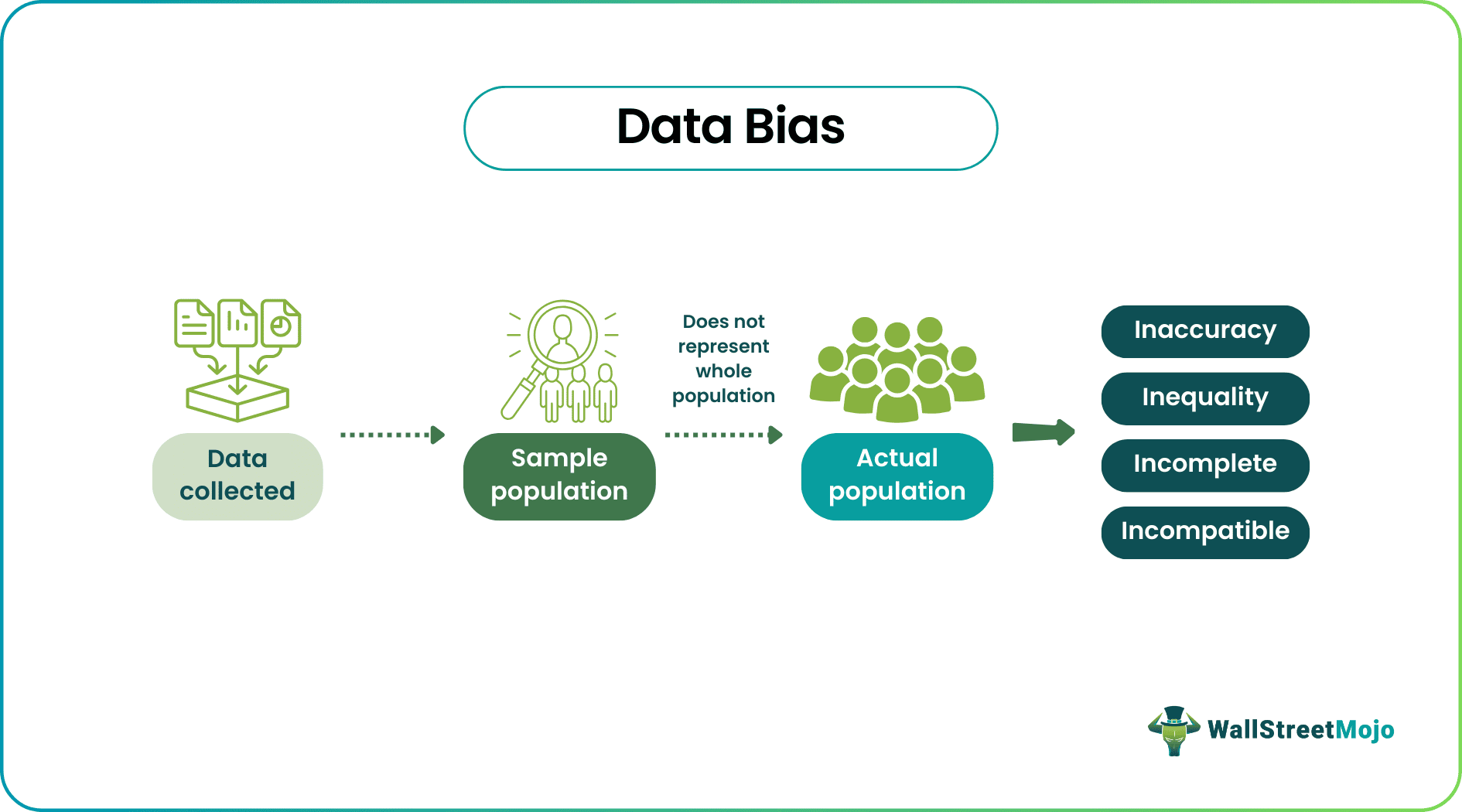
سوگیری دادهای به هر نوع تحریف یا نادرستی در دادهها اشاره دارد که میتواند بر فرآیند یادگیری و نتایج الگوریتمهای هوش مصنوعی تأثیر بگذارد. این سوگیری ممکن است ناشی از انتخاب نادرست دادهها، جمعآوری دادههای ناقص یا غیرنماینده، یا وجود تعصبات انسانی در فرآیندهای جمعآوری و پردازش دادهها باشد. به عبارت دیگر، سوگیری دادهای میتواند به عدم نمایندگی صحیح از واقعیتها و تنوع موجود در دادهها منجر شود.
1.2 اهمیت شناسایی سوگیری دادهای
شناسایی و درک سوگیری دادهای از آنجا اهمیت دارد که این سوگیری میتواند منجر به تصمیمات نادرست، افزایش نابرابری و تبعیض، و کاهش اعتبار و اعتماد به سیستمهای هوش مصنوعی شود. به عنوان مثال، الگوریتمهای استخدامی که بر اساس دادههای نادرست آموزش دیدهاند، ممکن است نامزدهای مناسب را نادیده بگیرند یا به نفع گروههای خاصی عمل کنند. این موضوع نه تنها به ضرر افراد آسیبدیده است، بلکه میتواند به تضعیف اعتبار سازمانها و نهادهای استفادهکننده از این الگوریتمها نیز منجر شود.

2. انواع سوگیری دادهای
2.1 سوگیری انتخابی
سوگیری انتخابی زمانی اتفاق میافتد که دادهها به طور غیرعمدی از یک گروه خاص یا ویژگیهای خاص جمعآوری شوند و نتوانند نمایندهی واقعی جامعه باشند. به عنوان مثال، اگر دادههای آموزشی یک الگوریتم تنها از یک منطقه جغرافیایی خاص جمعآوری شوند، الگوریتم ممکن است نتایج نادرستی برای سایر مناطق ارائه دهد. این نوع سوگیری میتواند به عدم دقت در پیشبینیها و تحلیلها منجر شود.
2.2 سوگیری تأییدی
سوگیری تأییدی به تمایل به جستجوی دادهها یا اطلاعاتی اشاره دارد که تأییدکنندهی باورها یا فرضیات قبلی هستند. این نوع سوگیری میتواند در فرآیند جمعآوری دادهها و انتخاب ویژگیها تأثیرگذار باشد و منجر به نادیده گرفتن دادههای متناقض شود. به عنوان مثال، اگر یک محقق تنها به دنبال دادههایی باشد که فرضیات خود را تأیید کند، احتمالاً نتایج نادرست و جانبدارانهای به دست خواهد آورد.
2.3 سوگیری ناشی از تعصبات انسانی
این نوع سوگیری زمانی رخ میدهد که تعصبات و پیشداوریهای انسانی در فرآیند جمعآوری و پردازش دادهها تأثیرگذار باشند. به عنوان مثال، اگر افرادی که دادهها را جمعآوری میکنند، نسبت به یک گروه خاص تعصبات منفی داشته باشند، این تعصبات میتوانند در دادههای نهایی منعکس شوند. این نوع سوگیری به ویژه در حوزههایی مانند استخدام، قضاوتهای قضایی و خدمات اجتماعی به شدت مشهود است.
2.4 سوگیری تاریخی
سوگیری تاریخی به وجود تعصباتی اشاره دارد که در دادههای تاریخی وجود دارند و میتوانند به الگوریتمهای هوش مصنوعی منتقل شوند. به عنوان مثال، دادههای مربوط به سوابق کیفری ممکن است به نفع گروههای خاصی باشند و منجر به تصمیمات ناعادلانه در سیستمهای قضایی شوند. این نوع سوگیری میتواند به تداوم نابرابریها و تبعیضها در جامعه کمک کند.

3. تأثیرات سوگیری دادهای بر هوش مصنوعی
3.1 کاهش دقت و کارایی
سوگیری دادهای میتواند به کاهش دقت و کارایی الگوریتمهای هوش مصنوعی منجر شود. الگوریتمهایی که بر اساس دادههای نادرست یا غیرنماینده آموزش دیدهاند، ممکن است نتایج نادرستی ارائه دهند و در عمل به درستی عمل نکنند. این موضوع میتواند به عواقب جدی در حوزههایی مانند پزشکی، مالی و امنیت منجر شود.
3.2 افزایش نابرابری و تبعیض
سوگیری دادهای میتواند منجر به افزایش نابرابری و تبعیض در جامعه شود. به عنوان مثال، الگوریتمهای استخدامی که بر اساس دادههای نادرست عمل میکنند، ممکن است به نفع گروههای خاصی عمل کنند و فرصتهای شغلی را برای دیگران محدود کنند. این نوع تبعیض میتواند به تضعیف اعتماد عمومی به نهادها و سازمانها منجر شود.
3.3 کاهش اعتماد عمومی
وجود سوگیری دادهای میتواند به کاهش اعتماد عمومی به سیستمهای هوش مصنوعی منجر شود. اگر افراد متوجه شوند که الگوریتمها به نفع گروه خاصی عمل میکنند یا نتایج نادرستی ارائه میدهند، اعتماد به این سیستمها کاهش مییابد و ممکن است افراد از استفاده از آنها خودداری کنند. این موضوع میتواند به کاهش پذیرش فناوریهای نوین در جامعه منجر شود.
3.4 تأثیر بر تصمیمگیریهای کلان
سوگیری دادهای نه تنها بر تصمیمات فردی تأثیر میگذارد، بلکه میتواند بر تصمیمگیریهای کلان در سطح سازمانها و دولتها نیز تأثیرگذار باشد. تصمیمات نادرست مبتنی بر دادههای سوگیرانه میتواند به سیاستگذاریهای نادرست و تخصیص نادرست منابع منجر شود که عواقب منفی برای جامعه به همراه خواهد داشت.
4. راهکارهای مقابله با سوگیری دادهای
4.1 جمعآوری دادههای متنوع و نماینده
برای کاهش سوگیری دادهای، لازم است که دادهها از منابع متنوع و نماینده جمعآوری شوند. این شامل جمعآوری دادهها از گروههای مختلف، مناطق جغرافیایی و ویژگیهای مختلف است تا اطمینان حاصل شود که دادهها به طور واقعی نمایندهی جامعه هستند. همچنین، استفاده از تکنیکهای نمونهگیری تصادفی میتواند به کاهش سوگیری در دادهها کمک کند.
4.2 استفاده از تکنیکهای پیشرفته
توسعهدهندگان میتوانند از تکنیکهای پیشرفته مانند یادگیری عمیق و الگوریتمهای تنظیم شده برای شناسایی و کاهش سوگیری دادهای استفاده کنند. این تکنیکها میتوانند به شناسایی الگوهای سوگیری و اصلاح آنها کمک کنند. به عنوان مثال، الگوریتمهای یادگیری ماشین میتوانند به طور خودکار سوگیریها را شناسایی و اصلاح کنند.
4.3 ارزیابی و آزمایش مداوم
الگوریتمها باید به طور مداوم ارزیابی و آزمایش شوند تا اطمینان حاصل شود که آنها به درستی عمل میکنند و تحت تأثیر سوگیری دادهای قرار ندارند. این شامل بررسی نتایج الگوریتمها و شناسایی هرگونه نابرابری یا تبعیض است. همچنین، ایجاد معیارهای ارزیابی برای سنجش عدالت و دقت الگوریتمها میتواند به شناسایی سوگیریها کمک کند.
4.4 شفافیت و توضیحپذیری
توسعهدهندگان باید تلاش کنند تا الگوریتمهای خود را شفافتر و قابل توضیحتر کنند. این شامل ارائه اطلاعات واضح درباره نحوه جمعآوری دادهها، فرآیندهای آموزشی و نحوه تصمیمگیری الگوریتمها است. این شفافیت میتواند به افزایش اعتماد عمومی کمک کند و به کاربران این امکان را بدهد که درک بهتری از عملکرد الگوریتمها داشته باشند.
4.5 آموزش و آگاهی
آموزش توسعهدهندگان و کاربران درباره سوگیری دادهای و تأثیرات آن میتواند به افزایش آگاهی و مسئولیتپذیری در این حوزه کمک کند. این آموزشها باید شامل مباحثی مانند شناسایی سوگیری، تأثیرات آن بر تصمیمگیری و راهکارهای مقابله با آن باشد. برگزاری کارگاهها و سمینارها در این زمینه میتواند به ارتقاء دانش و مهارتهای اخلاقی در میان توسعهدهندگان کمک کند.
4.6 همکاری بینالمللی
با توجه به جهانی شدن فناوری و الگوریتمها، همکاری بینالمللی در زمینه سوگیری دادهای ضروری است. تبادل دانش و تجربیات بین کشورها و سازمانهای مختلف میتواند به شناسایی و کاهش سوگیریها کمک کند. ایجاد انجمنهای بینالمللی برای بحث و بررسی مسائل مرتبط با سوگیری دادهای میتواند به ایجاد استانداردهای جهانی کمک کند.
نتیجهگیری
سوگیری دادهای یکی از چالشهای جدی در حوزه هوش مصنوعی و یادگیری ماشین است که میتواند تأثیرات عمیق و گستردهای بر دقت، عدالت و اعتماد به سیستمهای هوش مصنوعی داشته باشد. با شناسایی انواع سوگیری و تأثیرات آن، و با اتخاذ راهکارهای مناسب، میتوان به کاهش این سوگیریها و بهبود عملکرد الگوریتمها کمک کرد. در نهایت، ایجاد یک فرهنگ مسئولیتپذیری در توسعه و استفاده از هوش مصنوعی میتواند به ایجاد سیستمهایی عادلانهتر و قابل اعتمادتر منجر شود. این موضوع نه تنها به نفع توسعهدهندگان و شرکتهاست، بلکه به بهبود کیفیت زندگی افراد و جامعه نیز کمک خواهد کرد. با توجه به تأثیرات گستردهای که هوش مصنوعی بر زندگی روزمره ما دارد، تلاش برای کاهش سوگیری دادهای و ایجاد سیستمهای عادلانه و شفاف باید در اولویت قرار گیرد.
برای خواندن مطالب بیشتر به وبلاگ سر بزنید.