یادگیری ماشین (Machine Learning) یکی از شاخههای مهم هوش مصنوعی است که به سیستمها این امکان را میدهد تا از دادهها یاد بگیرند و بدون برنامهنویسی صریح، پیشبینیها یا تصمیمگیریهایی انجام دهند. الگوریتمهای یادگیری ماشین به دستههای مختلفی تقسیم میشوند و هر کدام دارای کاربردها و ویژگیهای خاص خود هستند. در این مقاله، به بررسی برخی از مهمترین الگوریتمهای یادگیری ماشین و نحوه کارکرد آنها خواهیم پرداخت.
یادگیری ماشین چیست؟
یادگیری ماشین (Machine Learning) به سیستمها این امکان را میدهد تا از دادهها یاد بگیرند و بدون نیاز به برنامهنویسی صریح، پیشبینیها یا تصمیمگیریهایی انجام دهند. به عبارت دیگر، یادگیری ماشین به کامپیوترها این توانایی را میدهد که از تجربیات گذشته خود بهرهبرداری کنند و با تحلیل دادهها، الگوها و روابط موجود را شناسایی کنند.
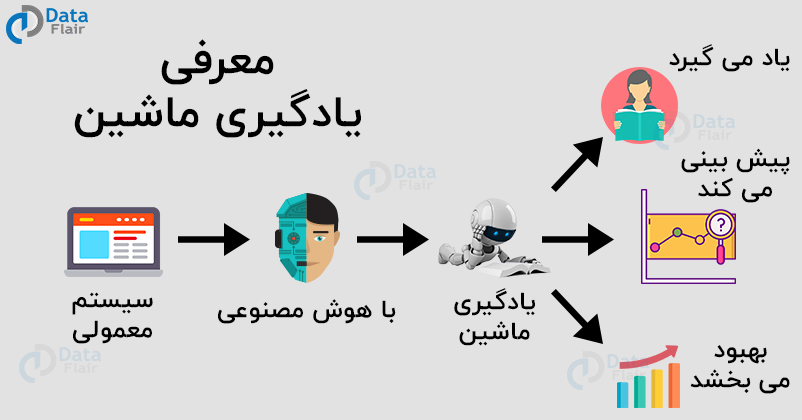
الگوریتم های یادگیری ماشین
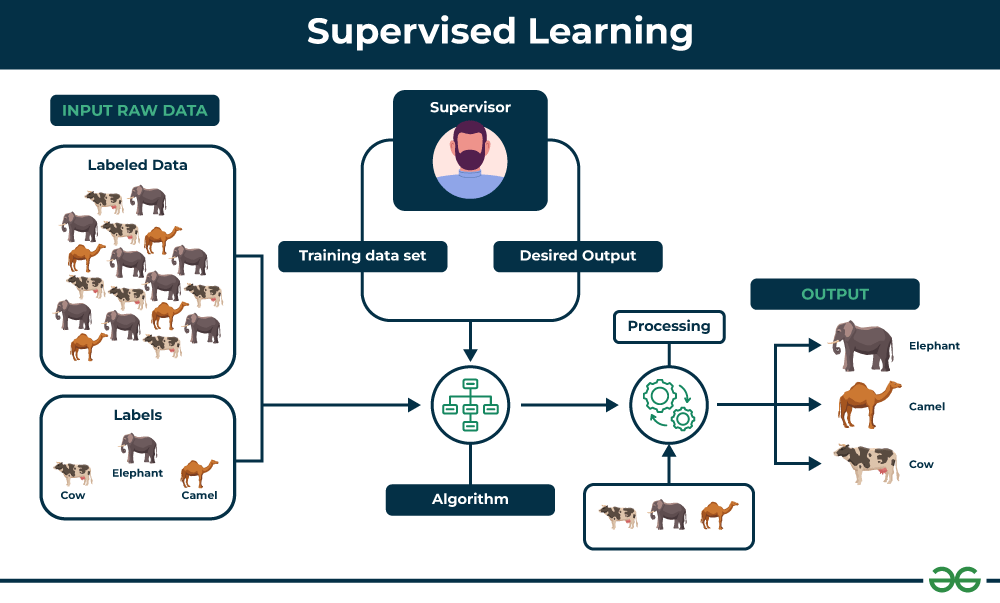
1. یادگیری نظارت شده (Supervised Learning)
یادگیری نظارت شده یکی از رایجترین روشهای یادگیری ماشین است که در آن مدل با استفاده از دادههای برچسبگذاری شده آموزش میبیند. در این روش، الگوریتم تلاش میکند تا یک تابع را بیاموزد که ورودیها را به خروجیهای صحیح مرتبط کند.
1.1. الگوریتمهای اصلی
- رگرسیون خطی (Linear Regression):
- نحوه کارکرد: این الگوریتم برای پیشبینی مقادیر عددی استفاده میشود. رگرسیون خطی سعی میکند یک خط مستقیم پیدا کند که بهترین تخمین را از دادهها ارائه دهد. این الگوریتم معمولاً با استفاده از روش حداقل مربعات (Least Squares) بهینهسازی میشود.
- کاربرد: پیشبینی قیمتها، تحلیل روندهای اقتصادی و غیره.
- درخت تصمیم (Decision Tree):
- نحوه کارکرد: درخت تصمیم با تقسیم دادهها به زیرمجموعهها بر اساس ویژگیهای مختلف، یک مدل درختی ایجاد میکند. هر گره در درخت نمایانگر یک ویژگی و هر برگ نمایانگر یک نتیجه است. این الگوریتم به سادگی قابل تفسیر است و میتواند برای طبقهبندی و رگرسیون استفاده شود.
- کاربرد: طبقهبندی ایمیلها به عنوان هرزنامه یا غیرهرزنامه، تشخیص بیماریها و غیره.
- شبکههای عصبی (Neural Networks):
- نحوه کارکرد: این الگوریتمها الهامگرفته از ساختار مغز انسان هستند و شامل لایههایی از نرونها هستند که به یکدیگر متصل شدهاند. شبکههای عصبی به طور خاص برای مسائل پیچیدهای مانند شناسایی تصویر و پردازش زبان طبیعی بسیار مؤثرند. این شبکهها با استفاده از الگوریتمهای یادگیری مانند پسانتشار (Backpropagation) آموزش میبینند.
- کاربرد: شناسایی چهره، تشخیص گفتار و ترجمه زبان.
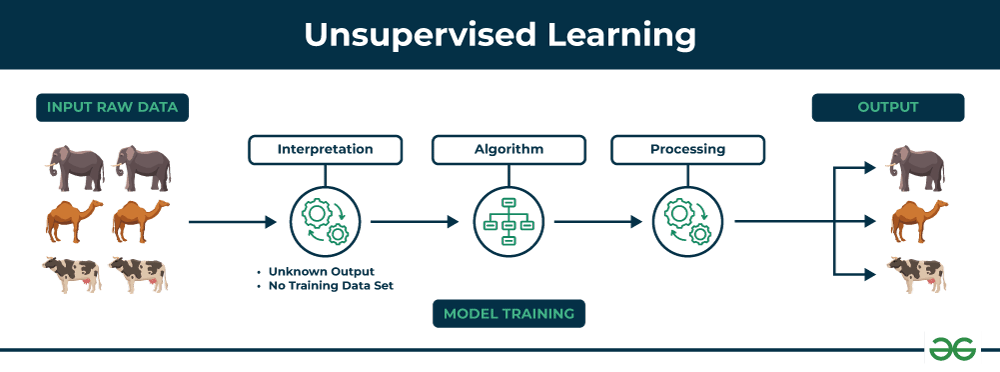
2. یادگیری بدون نظارت (Unsupervised Learning)
در یادگیری بدون نظارت، دادهها بدون برچسب ارائه میشوند و هدف الگوریتم شناسایی الگوها و ساختارهای نهفته در دادهها است. این نوع یادگیری به تجزیه و تحلیل دادههای بزرگ و پیچیده کمک میکند.
2.1. الگوریتمهای اصلی
- کلاسترینگ (Clustering):
- نحوه کارکرد: الگوریتمهایی مانند K-Means و DBSCAN برای گروهبندی دادهها به خوشههای مشابه استفاده میشوند. K-Means به صورت تصادفی K مرکز خوشه را انتخاب میکند و سپس دادهها را به نزدیکترین مرکز اختصاص میدهد.
- کاربرد: تحلیل بازار، شناسایی الگوهای مشتری و غیره.
- کاهش ابعاد (Dimensionality Reduction):
- نحوه کارکرد: الگوریتمهایی مانند PCA (Principal Component Analysis) برای کاهش ابعاد دادهها و حفظ ویژگیهای کلیدی آنها به کار میروند. این روش به تحلیل و تجسم دادهها کمک میکند.
- کاربرد: تجزیه و تحلیل دادههای تصویری و کاهش زمان پردازش.
3. یادگیری نیمهنظارت شده (Semi-Supervised Learning)
یادگیری نیمهنظارت شده ترکیبی از یادگیری نظارت شده و بدون نظارت است. در این روش، از مقدار کمی دادههای برچسبگذاری شده و مقدار زیادی دادههای بدون برچسب برای آموزش مدل استفاده میشود. این روش به ویژه در مواقعی که برچسبگذاری دادهها هزینهبر است، مفید است.
3.1. الگوریتمهای اصلی
- الگوریتمهای ترکیبی: این الگوریتمها معمولاً از تکنیکهای یادگیری نظارت شده و بدون نظارت به طور همزمان استفاده میکنند. به عنوان مثال، میتوانند از دادههای برچسبگذاری شده برای تقویت یادگیری از دادههای بدون برچسب استفاده کنند.
- کاربرد: شناسایی تصویر و پردازش زبان طبیعی که در آن برچسبگذاری تمام دادهها دشوار است.
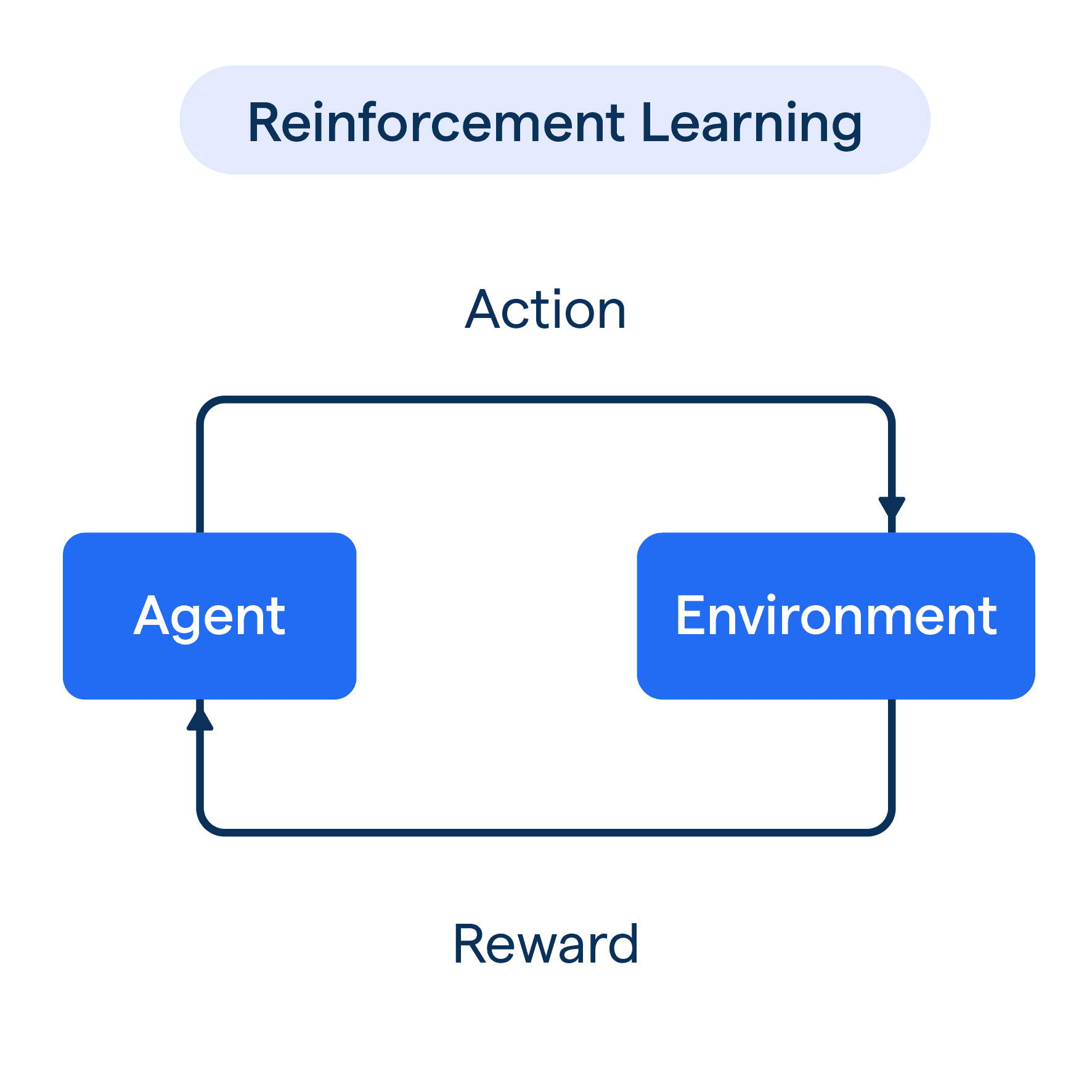
4. یادگیری تقویتی (Reinforcement Learning)
در یادگیری تقویتی، یک عامل (Agent) در یک محیط (Environment) عمل میکند و با دریافت پاداش یا تنبیه از محیط، یاد میگیرد که چگونه رفتار کند. این نوع یادگیری به طور گستردهای در بازیها و رباتیک استفاده میشود.
4.1. الگوریتمهای اصلی
- Q-Learning:
- نحوه کارکرد: این الگوریتم به عامل اجازه میدهد تا از تجربیات گذشته خود یاد بگیرد و بهترین عمل را برای حداکثر کردن پاداشهای آینده انتخاب کند. عامل از جدول Q برای ذخیره ارزش عملها در وضعیتهای مختلف استفاده میکند.
- کاربرد: بازیهای ویدیویی، رباتیک و سیستمهای کنترل.
- Deep Q-Networks (DQN):
- نحوه کارکرد: این الگوریتم از شبکههای عصبی برای تخمین تابع ارزش استفاده میکند و در بازیهای پیچیدهتر مانند شطرنج و Go به کار میرود. DQN به عامل اجازه میدهد تا با استفاده از یادگیری عمیق، الگوهای پیچیدهتری را شناسایی کند.
- کاربرد: بازیهای پیچیده، رباتیک و سیستمهای خودران.
5. انتخاب الگوریتم مناسب
انتخاب الگوریتم مناسب بستگی به نوع دادهها، هدف پروژه و منابع موجود دارد. در زیر چند نکته برای انتخاب الگوریتم مناسب ارائه میشود:
- نوع دادهها: اگر دادههای شما برچسبگذاری شدهاند، یادگیری نظارت شده گزینه مناسبی است. در غیر این صورت، یادگیری بدون نظارت یا نیمهنظارت شده ممکن است مناسبتر باشد.
- پیچیدگی مسئله: برای مسائل پیچیدهتر، الگوریتمهای یادگیری عمیق مانند شبکههای عصبی ممکن است بهترین گزینه باشند.
- زمان و منابع: برخی الگوریتمها نیاز به زمان و منابع بیشتری برای آموزش دارند. بنابراین، باید منابع موجود را در نظر گرفت.
6. چالشها و آینده یادگیری ماشین
یادگیری ماشین با چالشهایی نیز روبرو است که باید به آنها توجه کرد:
- کیفیت دادهها: دادههای ناکافی یا بیکیفیت میتوانند به نتایج نادرست منجر شوند. بنابراین، جمعآوری و پیشپردازش دادهها از اهمیت بالایی برخوردار است.
- تفسیر نتایج: برخی از الگوریتمها، به ویژه شبکههای عصبی، به عنوان “جعبه سیاه” شناخته میشوند و تفسیر نتایج آنها میتواند دشوار باشد.
- مسائل اخلاقی: استفاده از یادگیری ماشین در برخی زمینهها، مانند شناسایی چهره و نظارت، میتواند نگرانیهای اخلاقی و حریم خصوصی را به همراه داشته باشد.
آینده یادگیری ماشین
با پیشرفت تکنولوژی و افزایش حجم دادهها، انتظار میرود که یادگیری ماشین به طور فزایندهای در صنایع مختلف مورد استفاده قرار گیرد. از جمله روندهای آینده میتوان به موارد زیر اشاره کرد:
- یادگیری عمیق و شبکههای عصبی: با پیشرفتهای بیشتر در این حوزه، الگوریتمهای یادگیری عمیق بهبود یافته و تواناییهای بیشتری پیدا خواهند کرد.
- یادگیری خودکار (AutoML): این روند به کاربران غیرمتخصص این امکان را میدهد که به راحتی مدلهای یادگیری ماشین را ایجاد و بهینهسازی کنند.
- ادغام با سایر فناوریها: یادگیری ماشین به طور فزایندهای با فناوریهای دیگر مانند اینترنت اشیاء (IoT) و بلاکچین ادغام خواهد شد.
نتیجهگیری
الگوریتمهای یادگیری ماشین ابزارهای قدرتمندی هستند که میتوانند در حوزههای مختلفی از جمله پزشکی، مالی، بازاریابی و علوم اجتماعی کاربرد داشته باشند. با درک نحوه کارکرد این الگوریتمها و انتخاب مناسبترین آنها، میتوانیم از پتانسیلهای آنها بهرهبرداری کنیم و به حل مسائل پیچیدهتری بپردازیم. در آینده، با پیشرفت تکنولوژی و افزایش حجم دادهها، انتظار میرود که یادگیری ماشین نقش بیشتری در زندگی روزمره ما ایفا کند.
برای خواندن مطالب بیشتر به وبلاگ سر بزنید.